What Is ControlNet? Working, Models, and Uses
Through methods like pose, edge detection, and depth maps, ControlNet governs image synthesis precisely.

- ControlNet is defined as a group of neural networks refined using Stable Diffusion, which empowers precise artistic and structural control in generating images.
- It improves default Stable Diffusion models by incorporating task-specific conditions.
- This article dives into the fundamentals of ControlNet, its models, preprocessors, and key uses.
Table of Contents
What Is ControlNet?
ControlNet refers to a group of neural networks refined using Stable Diffusion, which empowers precise artistic and structural control in generating images. It improves default Stable Diffusion models by incorporating task-specific conditions. Lvmin Zhang and Maneesh Agrawala from Stanford University introduced it in the paper “Adding Conditional Control to Text-to-Image Diffusion Models” in February 2023.
To gain a deeper insight into the complexities of ControlNet, it becomes essential to delve into the concept of Stable Diffusion.
So, what exactly is Stable Diffusion?
Stable Diffusion is a deep learning model that employs diffusion processes to craft top-tier artwork from input images. In simple terms, if you give Stable Diffusion a prompt, it is trained to create a realistic image that matches your description.
This approach is a remarkable advancement compared to earlier text-image generators, as it adeptly handles intricate and abstract text descriptions. It achieves this by using a novel technique known as stable training, allowing the model to produce high-quality images in line with the provided text consistently.
Stable Diffusion shows versatility in generating various artistic styles, encompassing photorealistic portraits, landscapes, and abstract art. This algorithm finds utility in diverse applications, such as producing images for scientific research, crafting digital art, and shaping video game development.
For instance, game creators can use the model to generate in-game elements like characters and scenes from textual descriptions. Similarly, ecommerce platforms can enter a product description to generate a corresponding product design.
ControlNet is an expansion of the Stable Diffusion concept.
How ControlNet works
Let’s delve into its construction and training process to comprehend why ControlNet performs exceptionally well.
ControlNet provides us control over prompts through task-specific adjustments. For this to be effective, ControlNet has undergone training to govern a substantial image diffusion model. This enables it to grasp task-specific adjustments from both the prompt and an input image.
ControlNet, functioning as a complete neural network structure, takes charge of substantial image diffusion models, like Stable Diffusion, to grasp task-specific input conditions. ControlNet achieves this by replicating the weights of a major diffusion model into both a “trainable copy” and a “locked copy.” The locked copy conserves the learned network prowess from vast image data, while the trainable copy gets trained on task-specific datasets to master conditional control.
This process connects trainable and locked neural network segments using an exceptional convolution layer called “zero convolution.” In this layer, convolution weights progressively evolve from zeros to optimal settings through a learned approach. This strategy maintains the refined weights, ensuring strong performance across various dataset scales. Importantly, because zero convolution doesn’t introduce extra noise to deep features, the training speed matches that of fine-tuning a diffusion model. This contrasts with the lengthier process of training entirely new layers from scratch.

The Stable Diffusion Block Before and After the ControlNet Connections
Source: arXiv
See More: What Is the Metaverse? Meaning, Features, and Importance
Key ControlNet Settings
The ControlNet extension has numerous settings. Let’s break them down step by step.

Key ControlNet Settings
1. Input controls

Source: Stable Diffusion Art
Image canvas: You can easily drag and drop the input image onto this canvas. Alternatively, click the canvas to choose a file using the browser. The chosen input image goes through the selected preprocessor from the Preprocessor dropdown menu, generating a control map.
Write icon: Instead of uploading a reference image, this icon generates a fresh canvas with a white image, on which you can make direct scribbles.
Camera icon: Click this icon to take a picture using your device’s camera and use it as the input image. Browser permission to access the camera is necessary for this function.
2. Model selection

Enable: Decide whether to activate ControlNet.
Low VRAM: This is meant for GPUs with less than 8GB VRAM. This is an experimental option. Use it if GPU memory is limited or if you aim to enhance image processing capacity.
Allow Preview: Enable this to display a preview window next to the reference image. Select it for convenience. Use the explosion icon beside the Preprocessor dropdown menu to preview the preprocessor’s effect.
Preprocessor: The preprocessor (or “annotator”) readies the input image by detecting edges, depth, and normal maps. Choosing “None” retains the input image as the control map.
Model: Choose the ControlNet model for use. If a preprocessor is selected, opt for the corresponding model. The ControlNet model works in tandem with the Stable Diffusion model chosen at the top of the AUTOMATIC1111 GUI.
3. Control Weight
Below the preprocessor and model dropdown menus, you’ll find three adjustable sliders to fine-tune the Control effect: Control Weight, Starting Control Steps, and Ending Control Steps.

Let’s use an image to illustrate the effect of control weight. Consider an image of a sitting girl as shown below:

Source: Stable Diffusion Art
In the prompt, let’s instruct the software to create an image of a woman standing upright.
Prompt: A full-body view of a young female with hair exhibiting highlights, standing outside a restaurant. She has blue eyes, is dressed in a gown, and is illuminated from the side.
Weight: Weight is much like the importance given to the control map compared to the prompt. It’s like when you emphasize certain words more than others in a sentence. But here, it’s about how much attention is given specifically to the control map rather than the prompt itself. It’s like saying which part of the information is more important in a certain situation.
In ControlNet, weight helps decide how significant or crucial the control map is compared to the initial prompt. It’s a way to prioritize the importance of the control map’s information about the main topic being discussed.
The following images are produced using the ControlNet OpenPose preprocessor along with the application of the OpenPose model.

Source: Stable Diffusion Art


Source: Stable Diffusion Art
Observing the results, the ControlNet weight governs the extent to which the control map influences the image based on the prompt. A lower weight reduces ControlNet’s insistence on adhering to the control map.
The Starting ControlNet step is where ControlNet begins its work. When it’s set at 0, it’s the very first stage. The Ending ControlNet step shows when ControlNet stops affecting the process. When set at 1, it’s the last part where ControlNet has an impact.
4. Control Mode

ControlNet is used for both conditioning and unconditioning during a sampling step. This mode is the standard operation.
The prompt is more important: Gradually diminish the impact of ControlNet across U-Net injections (which total 13 in one sampling step). The outcome is that your prompt’s influence becomes greater than ControlNet’s.
ControlNet is more important: Disable ControlNet for unconditioning instances. Essentially, the CFG scale functions as a multiplier for the ControlNet’s impact.
It’s okay if the inner workings aren’t entirely clear. The labels of the options aptly describe their effects.
5. Resize mode

Resize mode governs the action taken when the dimensions of the input image or control map differ from those of the images to be produced. You needn’t be concerned about these choices if both images have the same aspect ratio.
To illustrate the impact of resize modes, let’s configure text-to-image generation for a landscape image while the input image/control map is in portrait orientation.
- Just Resize: Adjust the width and height of the control map separately to match the image canvas. This action alters the control map’s aspect ratio.
To illustrate, take a look at the following control map and the corresponding generated image:


With “Just Resize,” the control map’s proportions are adjusted to fit the dimensions of the image canvas
Source: Stable Diffusion Art
- Crop and resize: Adjust the image canvas to fit within the dimensions of the control map. Crops the control map to match the canvas size precisely.
Illustration: Just as the control map is cropped at its top and bottom sections, a similar effect is observed in the positioning of our subject, the girl.
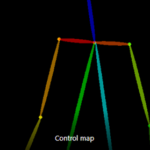

“Crop and Resize” adapts the image canvas to the control map’s dimensions while also cropping the control map accordingly.
Source: Stable Diffusion Art
- Resize and fill: Ensure the complete control map aligns with the image canvas. Expand the control map using empty values to match the canvas dimensions precisely. “Resize and fill” adjust the complete control map to match the image canvas and simultaneously extend the control map’s coverage.
See More: What Is Reinforcement Learning? Working, Algorithms, and Uses
ControlNet Models
ControlNet’s versatility extends to fine-tuning for generating images based on prompts and distinct image characteristics. This fine-tuning process enhances our capacity to control the outcomes of generated images. For instance, if we find an appealing image featuring a pose, ControlNet enables us to create something new while maintaining that pose.
This functionality shines brightest in scenarios where individuals have a clear shape or structure in mind but wish to experiment with alterations in color, surroundings, or object textures. Now, let’s explore the essential ControlNet models at users’ disposal.
1. Canny edge ControlNet model
Let’s examine a sample image that employs the Canny Edge ControlNet model as an example.

ControlNet Canny Model
Source: arXiv
Notice how, in the final results, the deer’s pose remains consistent while the surroundings, weather, and time of day exhibit variations. Below are a few outcomes from the ControlNet publication, showcasing different model implementations.

ControlNet Canny Result
Source: arXiv
The displayed outcome demonstrates that the ControlNet canny model can achieve impressive results without a specific prompt. Moreover, using the automatic prompt method notably enhances the results.
What’s intriguing is that with the Canny edge of a person at hand, we can guide the ControlNet model to create either a male or female image. Similarly, when using user prompts, the model reproduces the same image while replacing the male figure with a female one.
2. Hough lines
ControlNet enables the creation of remarkable variations in various architectures and designs, with Hough lines proving particularly effective in this regard. Notably, ControlNet excels at seamlessly transitioning materials, such as transforming to wood, a capability that sets it apart from other Img2Img methods.

ControlNet Hough Model for Interior Design
Source: arXiv
3. User scribble
Impeccable edge images aren’t always prerequisites for generating high-quality images through intermediate steps.
Even a basic user-generated scribble can serve as an adequate input. ControlNet can craft captivating images remarkably, as demonstrated above, based solely on these scribbles. However, using a prompt significantly enhances results in this scenario compared to the default (no prompt) option.

Output From User Scribble ControlNet Model
Source: arXiv
4. HED edge
HED edge is another ControlNet model for edge detection, yielding impressive outcomes. For example, let’s examine the realm of “Human Pose.” When employing ControlNet models for human pose, two alternatives are available:
- Human pose – Openpifpaf
- Human pose – Openpose

Regulating Both Pose and Style Using the ControlNet Openpifpaf Model
Source: arXiv
The Openpifpaf model yields more key points for hands and feet, offering excellent control over hand and leg movements in the resulting images. This effect is clearly demonstrated by the outcomes shown above.

Outputs From the ControlNet Openpose Model
Source: arXiv
When we have a basic idea of the person’s pose and desire for enhanced artistic authority over the environment in the ultimate image, the Openpose model is an ideal choice.
5. Segmentation map
When aiming for heightened control over diverse elements within an image, the Segmentation map ControlNet model emerges as the optimal choice.

Leveraging the ControlNet Segmentation Map Mode for Enhanced Manipulation of Distinct Objects
Source: arXiv
The illustrated diagram presents assorted room objects, each set within different contexts. Notably, the room’s color scheme and furniture consistently harmonize. This approach equally applies to outdoor scenes, allowing adjustments to factors like time of day and surroundings. For example, consider the following images.

Altering the Sky and Background by Harnessing the Capabilities of the ControlNet Segmentation Map Model
Source: arXiv
6. Normal maps
If the aim is to place greater emphasis on textures, lighting, and surface details, use the Normal Map ControlNet model.

Results Generated by the ControlNet Normal Map Model
Source: arXiv
See More: What Is Cortana? Definition, Working, Features, and Challenges
ControlNet Preprocessors
The initial phase in using ControlNet involves selecting a preprocessor. Enabling the preview can help understand the preprocessor’s actions. After preprocessing, the original image is no longer retained; only the preprocessed version becomes the input for ControlNet.
Let’s look at some key ControlNet preprocessors.
1. OpenPose preprocessors
OpenPose identifies crucial parts of human anatomy like head position, shoulders, and hands. It replicates human poses while excluding other specifics such as attire, hairstyles, and backgrounds.
To use OpenPose preprocessors, it’s essential to pair them with the openpose model selected from ControlNet’s Model dropdown menu. The OpenPose preprocessors encompass:
- OpenPose: Identifies eyes, nose, eyes, neck, shoulder, elbow, wrist, knees, and ankles
- OpenPose_face: OpenPose plus facial details
- OpenPose_hand: OpenPose plus hands and fingers
- OpenPose_faceonly: Covers only facial details
- OpenPose_full: All of the above
- dw_openPose_full: An upgraded rendition of OpenPose_full, DWPose introduces a novel pose detection algorithm derived from the research paper “Effective Whole-body Pose Estimation with Two-stages Distillation.” While sharing the same objective as OpenPose Full, DWPose excels in its performance.
2. Reference preprocessor
A novel set of preprocessors known as “Reference” is designed to generate images bearing resemblance to a chosen reference image. These images maintain an inherent connection to both the Stable Diffusion model and the provided prompt.
Reference preprocessors are unique because they are autonomous, operating independently of any control model. When using these preprocessors, the focus shifts solely to selecting the preferred preprocessor rather than the model itself. In fact, after selecting a reference preprocessor, the model dropdown menu will gracefully fade from view.
Three distinct reference preprocessors are at your disposal:
- Reference adain: Leverage the power of adaptive instance normalization for style transfer.
- Reference only: Establish a direct link between the reference image and the attention layers.
- Reference adain+attn: Combine the strengths of the approaches above synergistically.
Opt for one of these cutting-edge preprocessors to shape your creative output.
3. Depth
The depth preprocessor operates by making educated estimations about the depth attributes of the reference image.
There are several options available:
- Depth Midas: A tried-and-true depth estimation technique prominently featured in the Official v2 depth-to-image model.
- Depth Leres: This alternative provides enhanced intricacy. But it can also sometimes include the background when rendering.
- Depth Leres++: Taking things a step further, this option offers even greater intricacy than Depth Leres.
- Zoe: Positioned between Midas and Leres in terms of detail, this choice strikes a balance in the level of intricacy it delivers.
4. Line Art
The Line Art functionality specializes in producing image outlines, simplifying intricate visuals into basic drawings.
Several line art preprocessors are at your disposal:
- Line art anime: Emulates the distinct lines often seen in anime illustrations.
- Line art anime denoise: Similar to anime-style lines, but with fewer intricate details.
- Line art realistic: Captures the essence of realistic images through carefully crafted lines.
- Line art coarse: Conveys a sense of weightiness by employing realistic-style lines with a more substantial presence.
5. M-LSD
M-LSD (Mobile Line Segment Detection) is a dedicated tool for identifying straight-line patterns. It primarily extracts outlines featuring straightforward edges, making it particularly valuable for tasks such as capturing interior designs, architectural structures, street vistas, picture frames, and paper edges.
6. Normal maps
A normal map is a specification for the orientation of a surface. In the context of ControlNet, it takes the form of an image that designates the orientation of the surface under each pixel. Unlike color values, this image employs pixels to indicate the directional facing of the underlying surface.
Normal maps function like depth maps. They convey the three-dimensional composition inherent in the reference image.
Within the realm of normal map preprocessors:
- Normal Midas: This preprocessor estimates the normal map based on the Midas depth map. Similar to the characteristics of the Midas depth map, the Midas normal map excels at isolating subjects from their backgrounds.
- Normal Bae: Using the normal uncertainty methodology pioneered by Bae and colleagues, this preprocessor estimates the normal map. The resulting Bae normal map tends to capture details in both the background and foreground areas.
7. Scribbles
Scribble preprocessors transform images into hand-drawn-like scribbles reminiscent of manual sketches.
- Scribble HED: Leveraging the holistically nested edge detection (HED) technique, this preprocessor excels in generating outlines that closely resemble those produced by a human hand. As ControlNet’s creators state, HED is particularly apt for tasks such as image recoloring and restyling. The result from HED comprises rough and bold scribble lines.
- Scribble Pidinet: Using the Pixel Difference network (Pidinet), this preprocessor specializes in detecting both curved and straight edges. Its outcome resembles HED’s, albeit often yielding neater lines with fewer intricate details. Pidinet leans towards generating broad lines that focus on preserving main features, making it suitable for replicating essential outlines without intricate elements.
- Scribble xdog: Employing the EXtended Difference of Gaussian (XDoG) technique for edge detection, this preprocessor offers distinct advantages. The level of detail in the resulting scribbles is adjustable by fine-tuning the XDoG threshold, granting a versatile means to create scribbles that suit various needs. It’s imperative to calibrate the XDoG threshold and observe the preprocessor’s output to achieve the desired effect.
All of these preprocessors are designed to work harmoniously with the scribble control model.
8. Segmentation preprocessor
Segmentation preprocessors assign labels to identify the types of objects present within the reference image.
9. Shuffle preprocessor
The Shuffle preprocessor introduces an element of randomness to the input image, with its effects best harnessed alongside the Shuffle control model. This combination proves especially useful for transposing the color palette of the reference image. Notably, the Shuffle preprocessor distinguishes itself from other preprocessing techniques through its randomized nature, influenced by the designated seed value.
Employ the Shuffle preprocessor in tandem with the Shuffle control model, which works both with and without the Shuffle preprocessor.
The image below has been transformed using the ControlNet Shuffle preprocessor and Shuffle model, maintaining consistency with the previous prompt. The resulting color scheme shows a rough alignment with the hues of the reference image.

Source: Stable Diffusion Art
The following image has been generated solely using the ControlNet Shuffle model (no preprocessor). This composition closely resembles the original image structure, while the color scheme bears a resemblance to the shuffled version.

Source: Stable Diffusion Art
10. Color grid T2I adapter
The Color Grid T2i Adapter preprocessor diminishes the size of the reference image by a factor of 64 before subsequently restoring it to its initial dimensions. This process creates a grid-like pattern comprising localized average colors.
See More: What Is Narrow Artificial Intelligence (AI)? Definition, Challenges, and Best Practices for 2022
Uses of ControlNet
ControlNet finds utility across a spectrum of image-generation applications.
1. Generate images with a variety of compositions
Consider a scenario where the objective is to manipulate the arrangement of the astronaut and the background independently. In such cases, multiple ControlNets, typically two, can be employed to achieve this outcome.
To establish the desired pose for the astronaut, this reference image will serve as a foundational reference point.

Reference Image
Source: Stable Diffusion Art

Final Output
Source: Stable Diffusion Art
2. Replicating human pose
ControlNet’s predominant use is to replicate human poses, a task that has historically been challenging in terms of control, although this has changed recently. The input image for this process can either stem from an image produced through Stable Diffusion or be sourced directly from a physical camera.

Michael Jackson’s Concert
Source: arXiv
3. Revise a scene from a movie creatively
Imagine transforming the iconic dance sequence from Pulp Fiction into a serene session of yoga exercises taking place in a peaceful park setting.

Source: Stable Diffusion Art
This employs the combination of the ControlNet framework alongside the DreamShaper model.

Source: Stable Diffusion Art
4. Concepts for indoor space decoration
ControlNet, a versatile technology, finds innovative applications in interior design. By harnessing its capabilities, designers can craft captivating spaces. ControlNet’s M-LSD model, like a perceptive eye, identifies straight lines with precision, aiding in furniture arrangement and spatial optimization.
This technology transforms blueprints into vivid 3D visualizations, enabling clients to explore designs virtually. With ControlNet’s interactive controls, experimenting with various elements such as lighting, colors, and textures becomes effortless. This iterative approach fosters efficient collaboration between designers and clients.
Ultimately, ControlNet transcends traditional design boundaries, empowering professionals to create harmonious interiors that seamlessly merge aesthetics with functionality.
See More: What Is Cognitive Science? Meaning, Methods, and Applications
Takeaway
As image generation models advance, artists seek greater mastery over their creations. Unlike conventional Img2Img techniques, ControlNet introduces a groundbreaking avenue for governing elements like pose, texture, and shape in generated images. The versatility of models like ControlNet helps in diverse scenarios.
From envisioning altered daylight settings for environments to preserving architectural form while altering building hues, its utility spans time and design. Its impact extends to digital artistry, photography, and architectural visualization, empowering professionals to redefine possibilities and reimagine visual narratives.
Did this article help you understand how ControlNet is pushing the envelope of the image generation realm? Comment below or let us know on Facebook, X, or LinkedIn. We’d love to hear from you!
Image source: Shutterstock
MORE ON ARTIFICIAL INTELLIGENCE
- What Is Super Artificial Intelligence (AI)? Definition, Threats, and Trends
- Generative AI: Exploring Capabilities and Potential of Seven ChatGPT Alternatives
- The State of AI in Cybersecurity 2023: Insights About Use Cases
- The State of AI in Cybersecurity 2023: The “Lake Wobegon Effect”
- What Is a Chatbot? Meaning, Working, Types, and Examples







